- Introduction and problem
The total size of data saved on a backup environment is complex, and subject to many misunderstandings. When a customer buys, let’s say 1TiB backup storage, they usually expect to be able to save 1TiB of data stored on their different machines. But they may probably want to keep multiple versions of each backup, for example one a day for 4 days. Thus it could only save 250GiB of different backups (1TiB / 4). That said, the data usually changes little from one day to the following, and Avamar has a data deduplication algorithm. It's a safe bet that it can save much more than 250GiB, even with 4 versions, perhaps 900GiB for example.
Therefore, RG had to implement a billing algorithm that takes into account the specificities of the DELL EMC Avamar deduplication model.
In order to better understand the algorithm on which the RG System billing model is based, we will start by defining the terms necessary to understand the model, then we will see 3 different theoretical cases, before concluding on the general formulation of the model.
1. Terms and definitions
Deduplication concepts
Deduplication is a recurring term in the world of backup. Understanding this notion is key in order to properly address this paper.
Deduplication is a form of data compression that reduces storage requirements by eliminating redundant data. The storage medium therefore retains a single copy of this data.
When initializing a backup, DELL EMC Avamar will compare the data on the environment and the source data selected on the machine. Once the analysis is done, DELL EMC Avamar will only send to the environment the missing data (fig.1).
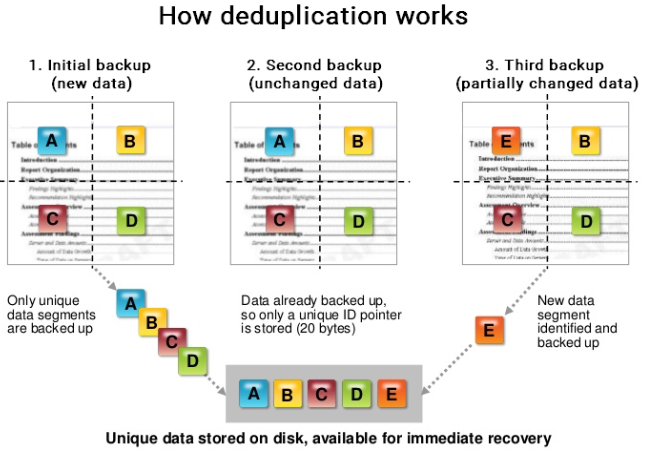
fig.1. depluplication
When a backup policy is performed regularly, duplicates between different versions of the same file inevitably appear. So instead of storing X versions of the same document, Avamar is able to say that there is no need for this data because it is already present. If the document changes slightly, DELL EMC Avamar will be able to detect this change and finally send only the part of the document that has changed to the environment. The storage space is then preserved from a useless duplicate.
We will consider in this document that there are two notions of deduplication: deduplication between machines and deduplication between backups of the same machine.
The RG billing model tries to estimate, from the backups of a policy, what data is actually already stored on the environment for that policy. For simplicity concerns, RG will only consider deduplication between backups of the same machine, and not deduplication between backups of two different machines.
In a very general way, our model is based on a "basic deduplication rate" corresponding to the percentage of the estimated similar data between two consecutive backups of the same size made at one day interval. The deduplication rate can vary depending on the customer's usage. If you're using files with a low commonality rate, a penalty will be applied.
In the following examples, we consider to simplify a basic deduplication rate without penalty of 90%.
Source data
Source data represents the size of the data on the machines to be backed up, regardless of the number of backup versions to retain (retention), or deduplication. These are selected in the Datasets form in the backup wizard available in the page of backup management (fig.2)
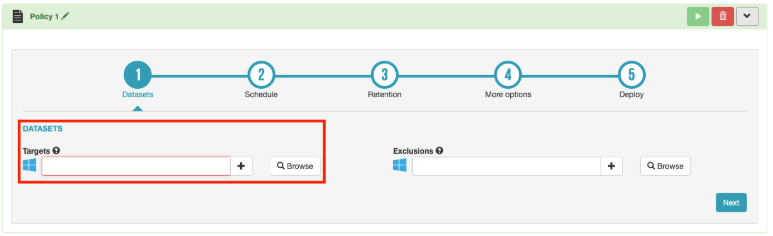
fig.2. Datasets
If you have 5 machines with a backup directory of 50GiB each, your source data is worth 5 * 50GiB = 250GiB. If you launch a daily backup on your IT infrastructure, your source data will be visible in the page of the environment's activity, in the box "Data protected" (fig.3).

fig.3. Data Protected
Restorable data
Restorable data is the sum of the data you can restore from your environment, regardless of deduplication. For example, if you have 250GiB of source data, with one backup per day and 4 days retention, you will have 4 versions of each backup, so 250 * 4 = 1000GiB of restorable data. The restorable data can be seen in the backup statistics page in “Consumption” (fig.4.).
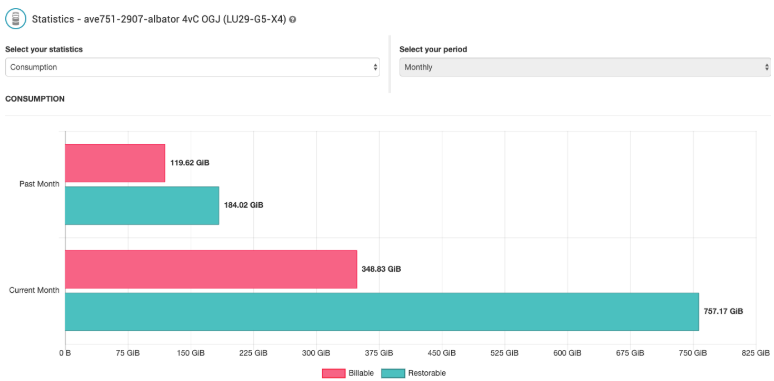
fig.4. Consumption
The data actually consumed on the physical environment
The actual data consumed on a physical environment corresponds to the disk space used on the Avamar server. This sum will be much less than the restorable data, thanks to the Avamar deduplication. If the customer owns his environment, this data will be visible in the “Statistics” page of the environment, in the "Capacity" field (fig.5). For a shared environment, each customer obviously cannot see the data actually consumed, which only makes sense for all the customers present on the physical environment, since the space is not divided between customers but between deduplicated data.
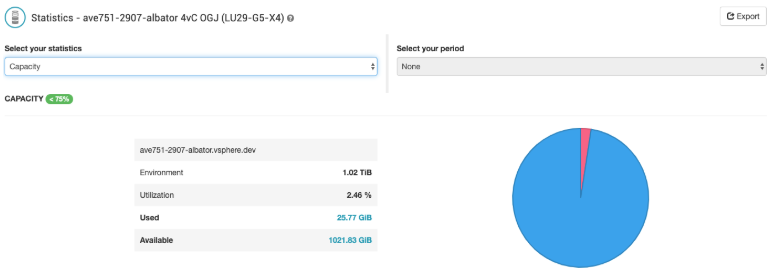
fig.5. Capacity
Virtual backup environnement
In order to share a single physical environment with multiple customers RG had to introduce the concept of “virtual environment” (fig.6.). It’s a secure virtual segregation of the physical environment that’s created for each customer. This allows the customer to have their own boxes. The changes from one customer will not affect the others.
fig.6. Virtual environment
Billable data
The concept of billable data is used to bill multiple customers in the case of a physical environment shared between them. Indeed, none of the three previous notions can effectively allow to bill customers according to their respective consumption:
- Source data does not account for retention - charging only for source data would be unfair, as a customer with too much retention might consume far too much space compared to what he or she pays;
- Restorable data does not take deduplication into account - charging only with restorable data would therefore encourage customers to put very low retention, whereas one of Avamar's strengths is precisely the small increase in actual consumption when we increase retention, thanks to deduplication;
- The actual data consumed by a machine on the physical environment is global, Avamar does not know which machine consumes what, but only the total disk space used.
RG has therefore created a model to estimate a backup consumption for a machine, depending on the size of its backups and its retention the: “billable data”. It is this consumption multiplied by its price per GiB which is used to invoice it.
Like the restorable data, the billable data can be seen in the page of the environment statistics, in "Consumption" (fig.4).
- Simple case
The first case we are going to study is a simple theoretical case based on a series of daily backups of the same size. This will allow us to address the fundamentals of how the algorithm works.
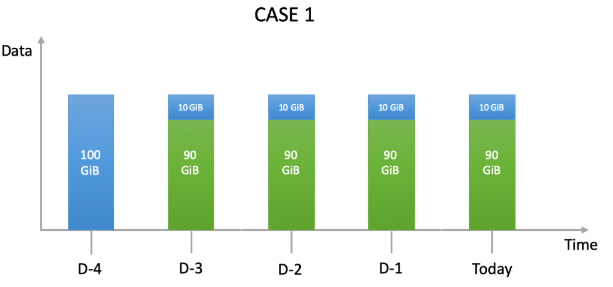
Suppose (fig.1) that a user implements a backup policy on an agent. He wants to do 1 backup job a day and wants to keep each backup 5 days. The selected source data is 100GB. Basic deduplication rate is 90%.
At this point, you should be aware that our billing algorithm run after each activity (and at least daily) to calculate the amount of non-deduplicated data in the restorable data. The algorithm will consider all the restorable backups of the machine when it is executed. The MAXIMUM daily value of a month is the billable data of the month.
Fig.1 shows the behavior of our billing algorithm in this case. It considers as new data, sent to the AVAMAR environment, volumes in BLUE. Only the non-deduplicated BLUE volume will be taken into account. In GREEN you find the data volumes considered deduplicated which will be ignored by the billing algorithm. There are 5 restorable backups made since D-4 present in the environment.
Detail of the algorithm that allows us to estimate non-deduplicated volumes:
1- The volume of the first backup (D-4) is fully taken into account: 𝐵0
2- For the following backup volumes (𝐵𝑗), we do not take into account the non-deduplicated volumes:
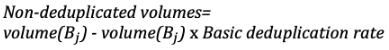
3- In the end we have the following equation as formula, with “n” the maximum number of restorable backups (here 5):
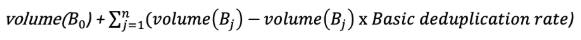
In this case, the total daily billable backup volume for the policy will be:
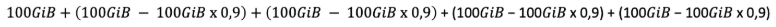
=
the addition of blue volumes (fig.1)
=
100GiB + 4 x 10GiB = 140GiB billable
- Case with irregular time intervals between backups
This second case will allow us to better understand how our model takes into account the influence of time between backups.
We have postulated that the more time passes between backups, the more changes should be expected. In order to make our calculations consistent, we had to consider that the basic deduplication rate is a deduplication rate for a day.
Therefore, even if there is no backup over the time period, the deduplication rate is impacted. The backup which is the cut-off period will therefore be considered to have more billable non-deduplicated data than the previous one.
The "real deduplication rate" will be referred to as the percentage of similar data between two consecutive backups of the same size with any time interval between backups. The calculation method of the actual deduplication rate, with respect to the basic deduplication rate and the time interval Δt between two backups (in days), is as follows:
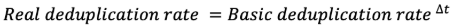
Note that real deduplication should never be less than basic deduplication. Indeed, if a user decides to make several backups a day, it's probably because his data changes a lot. We will therefore adopt the following formula:
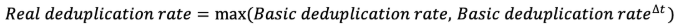
By reusing the previous formulation we have:
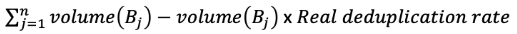
To illustrate this, suppose a user sets up a single backup job on an agent. He wants to do a backup job every day except on day 3 and wants to keep each backup 5 days (fig.2). The selected source data is 100GB. Basic deduplication rate is 90%.
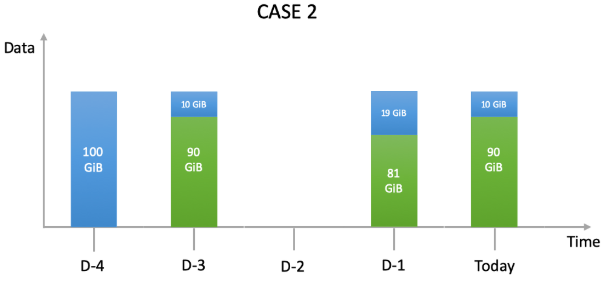
This time, our billing algorithm considers in D-1 a non deduplicated data value of:
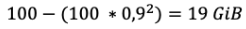
In this case, the total billable backup volume for the policy will be:
100GiB + 10GiB + 19GiB + 10GiB = 139GiB billable
- Case with variable backup volumes
This third case will allow us to better understand how our model takes into account the variations of the volume of the source data of a backup policy.
The idea is that if a backup is bigger than the previous, we consider that there is no deduplicated data in the new data. The deduplication rate will only be considered on the smaller backup.
Now suppose that a user sets up a single backup job on an agent. He wants to do 1 backup job a day and wants to keep each backup 5 days. However, the source data volumes are variable for days D-2 and D-1 (fig.3). The selected source data is 100GiB. Basic deduplication rate is 90%.
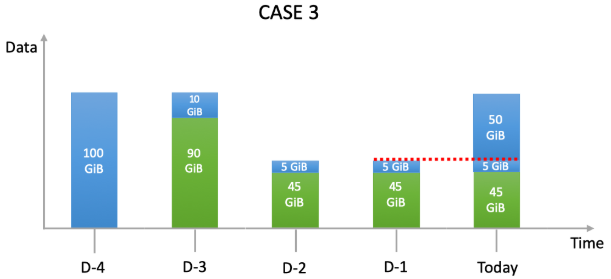
Here, our billing algorithm considers today (Today) a larger non deduplicated data value:
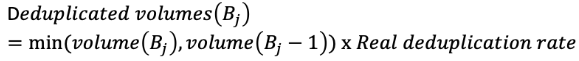
So:
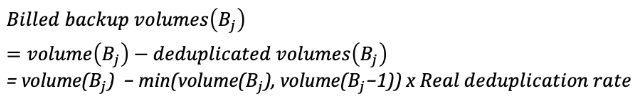
In this case, the total billable backup volume for the policy will be:
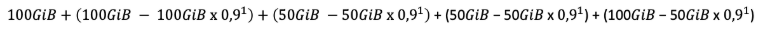
=
the addition of blue volumes (fig.3)
=
100GiB + 10GiB + 2 x 5GiB + 55GiB = 175GiB billable
- General formula
Here is the mathematical formula we use every day to calculate backup consumption values.
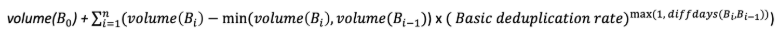
With:
B = backup
B0 = initial backup
volume = size of the backup in bytes
diffdays(Bi,Bi-1) = Number of days of difference between the last backup (i-1) and the current one (i)
- Application to billing
The last formula allows to estimate at time t the consumption of each machine, and therefore of a customer account, from its backups available at this moment in the backup environment. This algorithm will be applied every day on all machines. The billable data of an account for a month is the sum of the maximum daily consumption of all their machines during that month.
- Multiple policies on an agent
If an RG agent has more than one policy, we group their backups by policy before applying the billing algorithm on each policy. The consumption of the agent will therefore correspond to the sum of the maximum consumption of each policies.