Introduction et problématique
La notion de taille totale des données sauvegardées sur un environnement est complexe, et sujette à beaucoup d'incompréhensions. Quand un client achète, disons 1Tio de sauvegarde, il s'attend généralement à pouvoir sauvegarder 1Tio de donnée sur ses différentes machines. Mais il voudra probablement garder plusieurs versions des sauvegardes, disons pour l'exemple une par jour pendant 4 jours. Il ne pourrait du coup sauvegarder que 250Gio de données (1Tio / 4). Cela dit, les données changent généralement assez peu d'un jour à l'autre, et Avamar possède un algorithme de déduplication des données. Il y a donc fort à parier qu'il puisse sauvegarder beaucoup plus que 250Gio, même avec 4 versions, peut-être par exemple 900Gio.
RG a donc dû mettre en place un algorithme de facturation qui prenne en compte les spécificités du modèle de déduplication Avamar.
Afin de mieux comprendre l’algorithme sur lequel se base le modèle de facturation RG System, nous allons commencer par définir les termes nécessaires à la compréhension du modèle, nous verrons ensuite 3 cas théoriques différents, avant de conclure sur la formulation générale du modèle.
1. Termes et définitions
Notions de déduplication:
La déduplication est un terme récurrent dans le monde de la sauvegarde. Comprendre cette notion est essentiel afin d’aborder correctement ce papier.
La déduplication est une forme de compression de données qui permet de réduire les besoins en espace de stockage en supprimant les données redondantes. Le support de stockage conserve donc un seul exemplaire de chaque donnée.
Lors de l'initialisation d’une sauvegarde, Avamar va faire un comparatif entre les données présentes sur l'environnement et les données sources sélectionnées sur la machine. Une fois l’analyse faite, Avamar ne va envoyer sur l'environnement que les données non existantes (fig.1).
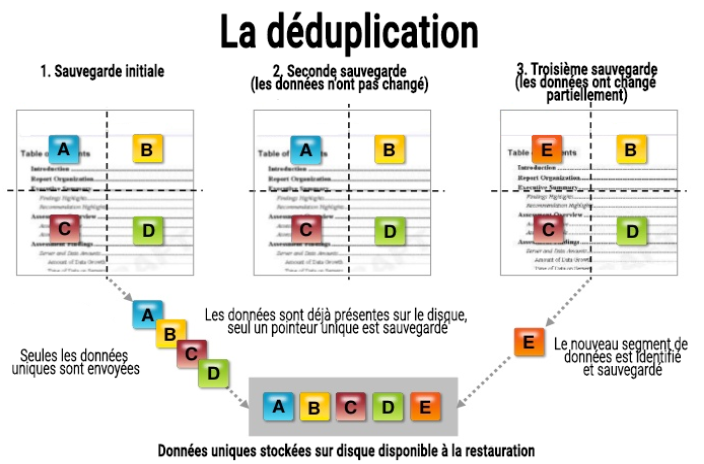
fig.1. depluplication
Quand une politique de sauvegarde est effectuée régulièrement, des doublons entre différentes versions d’un même fichier apparaissent inévitablement. Donc au lieu de stocker X versions du même document, Avamar est capable de dire qu’il n’y a pas besoin de cette donnée car elle est déjà présente. Si le document change légèrement, Avamar sera capable de détecter ce changement enfin de n’envoyer sur l'environnement que la partie du document qui a changé. L’espace de stockage est donc préservé d’un doublon inutile.
Nous allons considérer dans ce document qu’il existe deux notions de déduplication : la déduplication entre machines et la déduplication entre les sauvegardes d’une même machine.
Le modèle de facturation RG essaie d’estimer, à partir des sauvegardes d’une machine, quelles sont les données effectivement déjà stockées sur l’environnement pour cette machine. On ne considérera dans RG, pour des raisons de simplicité, que la déduplication entre les sauvegardes d’une même machine, et pas la déduplication entre les sauvegardes de deux machines différentes.
De manière très générale, notre modèle repose sur un "taux de déduplication de base" correspondant au pourcentage des données similaires estimées entre deux sauvegardes consécutives de la même taille effectuées à un jour d'intervalle. Ce taux peut varier en fonction de l'utilisation du client. Si le client utilise des fichiers avec un faible taux de déduplication, une pénalité sera appliquée.
Dans les exemples suivants, on considérera pour simplifier un taux de déduplication de base sans pénalité de 90 %.
Les données sources
Les données sources représentent la taille des données présentes sur les machines à sauvegarder, indépendamment de nombre de versions de sauvegarde à conserver (rétention), ou de déduplication. Celles-ci sont sélectionnées dans le formulaire “Jeux de données” de l'assistant de sauvegarde disponible dans la page de gestion de la sauvegarde (fig.2)
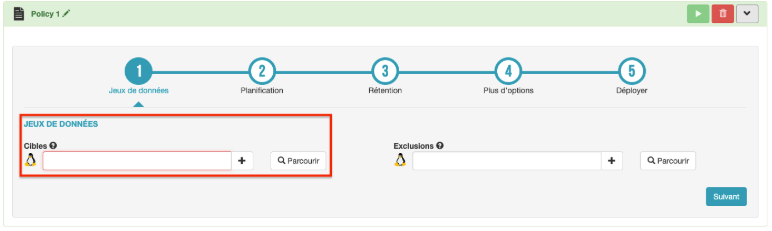
fig.2. Jeux de données
Si vous avez 5 machines avec sur chacune un répertoire à sauvegarder de 50Gio, vos données sources font 5*50 = 250Gio. Si vous lancez, une sauvegarde par jour sur votre parc, le cumul des données sources de la période sélectionnée sera visible dans la page d’activité de l'environnement dans l'encart « Données Protégées » (fig.3).

fig.3. Données protégées
Les données restaurables
Les données restaurables correspondent à la somme totale des données que vous pouvez restaurer sur votre environnement, indépendamment de la déduplication. Si vous avez par exemple 250Gio de données source, avec une sauvegarde par jour et une rétention de 4 jours, vous aurez donc 4 versions de chaque sauvegarde, et donc 250*4 = 1000Gio de données restaurables. Les données restaurables sont visibles dans la page de l’activité de l'environnement dans la page de statistique sous “Consommation”.
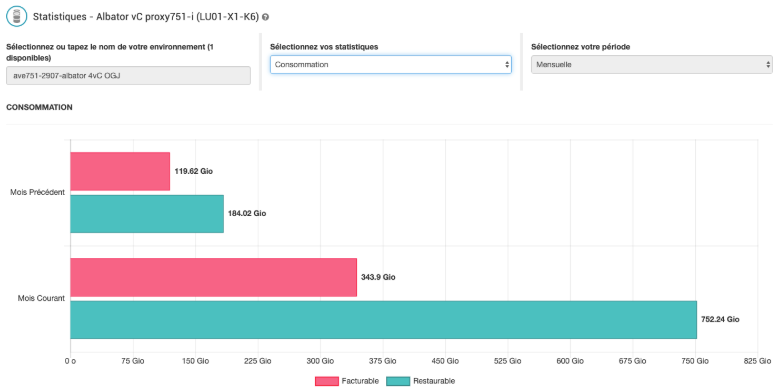
fig.4. Consommation
Les données réellement consommées sur l'environnement physique
Les données réellement consommées sur un environnement physique correspondent à l'espace disque utilisé sur le serveur Avamar. Cette somme sera très inférieure aux données restaurables, grâce à la déduplication d'Avamar. Si le client est propriétaire de son environnement, ces données seront visibles dans la page Statistiques de l'environnement, dans l'encart "Capacité" (fig.5). Pour un environnement mutualisé, chaque client ne peut évidemment pas voir les données réellement consommées, qui n'ont de sens que pour l'ensemble des clients présents sur l'environnement physique.
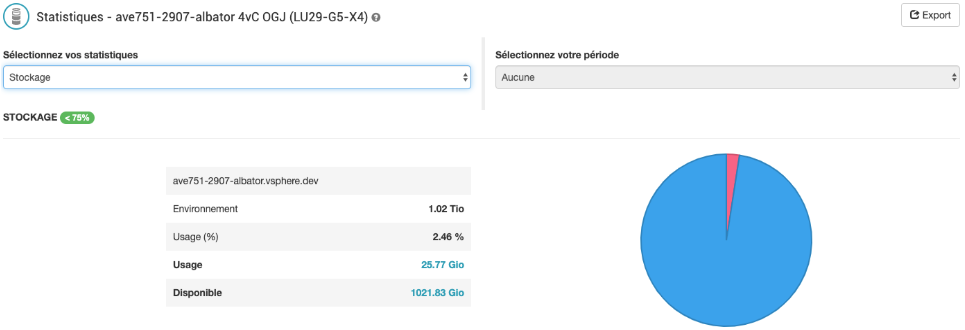
fig.5. Stockage
Environnement de sauvegarde virtuel
Afin de partager un même environnement physique avec plusieurs clients, RG a dû introduire le concept d'«environnement virtuel» (fig.6). Il s’agit d’une séparation virtuelle sécurisée de l’environnement physique créé pour chaque client de sorte que les changements d'un client n'affectent pas les autres. Ceci permet au client d'avoir son environnement dédié.
fig.6. Environnement virtuel
Les données facturables à la consommation
La notion de données facturables à la consommation est utilisée pour pouvoir facturer plusieurs clients dans le cas d'un environnement physique mutualisé. En effet, aucune des trois notions précédentes ne permet de facturer efficacement les clients en fonction de leurs consommations respectives :
- les données sources ne prennent pas en compte la rétention - ne facturer qu'en fonction des données sources serait donc très risqué, car un client avec une rétention trop importante risquerait de consommer beaucoup trop d'espace par rapport à ce qu'il paye ;
- les données restaurables ne prennent pas en compte la déduplication - ne facturer qu'en fonction des données restaurables encouragerait donc les clients à mettre une rétention très faible, alors qu'un des atouts d'Avamar est justement la faible augmentation de la consommation réelle quand on augmente la rétention, grâce à la déduplication ;
- les données réellement consommées sur l'environnement physique sont globales, Avamar ne permet pas de savoir quel client consomme quoi, mais seulement l'espace disque total utilisé.
RG a donc créé un modèle permettant d'estimer une consommation de sauvegarde (données facturables) pour une machine, en fonction de la taille de ses sauvegardes et de sa rétention. C'est cette consommation multipliée par son prix au giga qui est utilisée pour le facturer. Comme les données restaurables, les données facturables sont visibles dans la page statistique de l'environnement, dans l'encart "Consommation" (fig.4).
-
Cas simple
Le premier cas que nous allons étudier est un cas théorique simple qui repose sur une suite de sauvegardes journalière de mêmes taille. Ceci va nous permettre d’aborder les notions fondamentales du fonctionnement de l’algorithme.
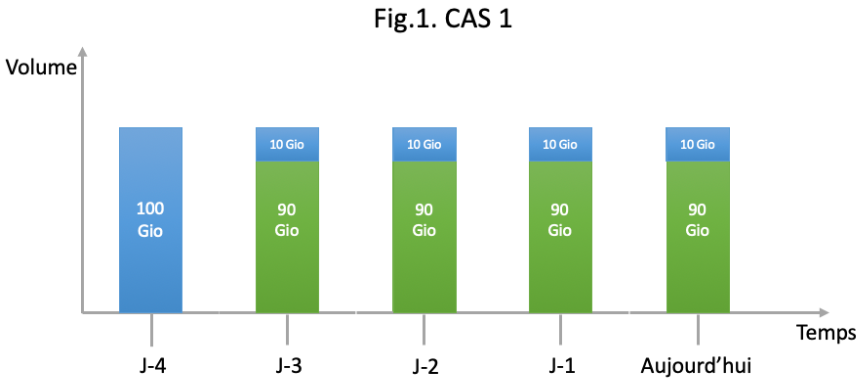
Supposons (fig.1) qu’un utilisateur mette en place une politique de sauvegarde sur un agent. Celui-ci souhaite faire 1 job de sauvegarde par jour et souhaite garder chaque sauvegarde 5 jours. La donnée source sélectionnée est de 100Gio. Le taux de déduplication de base est de 90%.
À ce stade, vous devez savoir que notre algorithme de facturation s'exécute après chaque activité (et au moins quotidiennement) pour calculer la quantité de données non dédupliquées dans les données restaurables. L'algorithme prendra en compte toutes les sauvegardes restaurables de la machine lors de son exécution. C’est la valeur MAXIMALE journalière sur le mois qui sera pris en compte pour la facturation.
La fig.1 montre le comportement de notre algorithme de facturation dans ce cas. Il considère comme nouvelle donnée, envoyée sur l’environnement Avamar, les volumes en BLEU. Seul le volume BLEU non dédupliqué sera pris en compte. En VERT vous retrouvez les volumes de données considérés dédupliqués qui seront ignorés par l’algorithme de facturation. On retrouve les 5 backups sauvegardes effectuées depuis J-4 présentes dans l'environnement.
Détail de l’algorithme permettant d’estimer les volumes non dédupliqués:
1- Le volume de la première sauvegarde (J-4) est entièrement pris en compte soit : 𝐵0
2- Pour les volumes des sauvegardes suivantes (𝐵𝑗), on ne prend pas en compte que les volumes non dédupliqués soit :
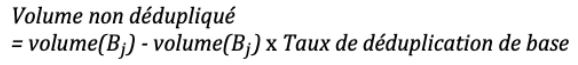
3- Au final nous avons donc comme formule l’équation suivante, avec n le nombre maximum de backups restaurables (ici 5) :
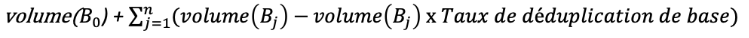
Dans ce cas, le volume total de sauvegarde facturable du jour pour la machine sera donc :
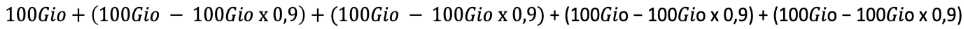
=
l'addition des volumes bleus (fig.1)
=
100Gio + 4 x 10Gio = 140Gio facturables
- Cas avec des intervalles de temps irrégulier entre les sauvegardes
Ce second cas va nous permettre de mieux comprendre comment notre modèle prend en compte l'influence du temps entre les sauvegardes.
Nous avons établi comme postulat que plus il se passe de temps entre deux sauvegardes, plus il devrait y avoir de changement être celles-ci. Afin de rendre nos calculs cohérents, nous avons dû considérer que le taux de déduplication de base correspond à un taux de déduplication pour un jour.
Par conséquent, même s’il n’y a pas de sauvegarde sur la période de temps, le taux de déduplication est impacté. La sauvegarde qui suit la période de coupure sera donc considérée comme ayant plus de données non dédupliquées facturables que la précédente.
On appellera par la suite “taux de déduplication réel” le pourcentage des données semblables entre deux sauvegardes consécutives de même taille avec un intervalle de temps quelconque entre les sauvegardes. La méthode de calcul du taux de déduplication réel, par rapport au taux de déduplication de base et à l’intervalle de temps ∆t entre deux sauvegardes (en jours), est la suivante:
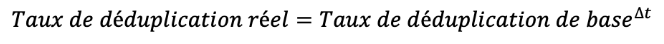
A noter qu’on considère que la déduplication réelle ne doit jamais être inférieure à la déduplication de base. En effet, si un utilisateur décide de faire plusieurs sauvegardes par jour, c’est probablement parce que ses données changent beaucoup. On adoptera donc la formule suivante:
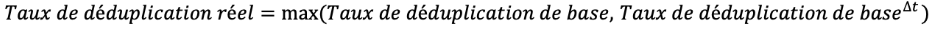
Soit en reprenant la formulation précédente :
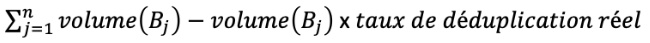
Pour illustrer cela, supposons qu’un utilisateur mette en place un job unique de sauvegarde sur un agent. Celui-ci souhaite faire un job de sauvegarde par jour sauf le jour 3 et souhaite garder chaque sauvegarde 5 jours (fig.2). La donnée source sélectionnée est de 100Gio. Le taux de déduplication de base est de 90%.
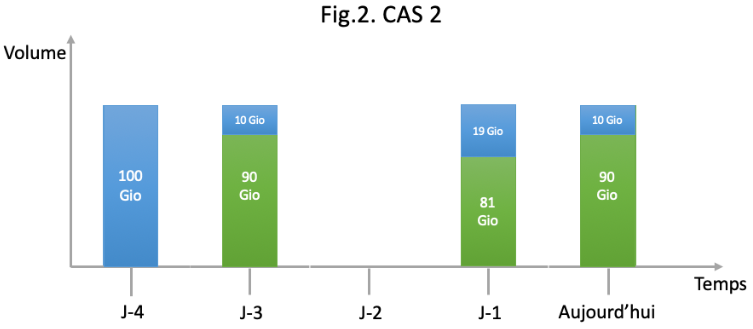
Cette fois, notre algorithme de facturation considère en jour J-1 une taille de données non dédupliquées de :
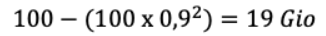
Dans ce cas, le volume total de sauvegarde facturable pour la machine sera donc :
100Gio + 10Gio + 19Gio + 10Gio = 139Gio facturables
- Cas avec des volumes de sauvegarde variables
Ce troisième cas va nous permettre de mieux comprendre comment notre modèle prend en compte les variations du volume des données sources d’une politique de sauvegarde.
L’idée, c’est que si une sauvegarde est plus importante que la sauvegarde de la veille, on considère qu’il n’y a aucune donnée dédupliquée dans les nouvelles données. On ne considérera donc le taux de déduplication que sur la sauvegarde la plus petite taille.
Supposons maintenant qu’un utilisateur mette en place un job unique de sauvegarde sur un agent. Celui-ci souhaite faire 1 job de sauvegarde par jour et souhaite garder chaque sauvegarde 5 jours. Cependant, les volumes de données sources de ces dernières sont variables pour les jours J-1 et J-2. La donnée source sélectionnée est de 100Gio. Le taux de déduplication de base est de 90%.
Cette fois les données de la politique de sauvegarde sont amenées à fortement varier sur la période (fig.3).
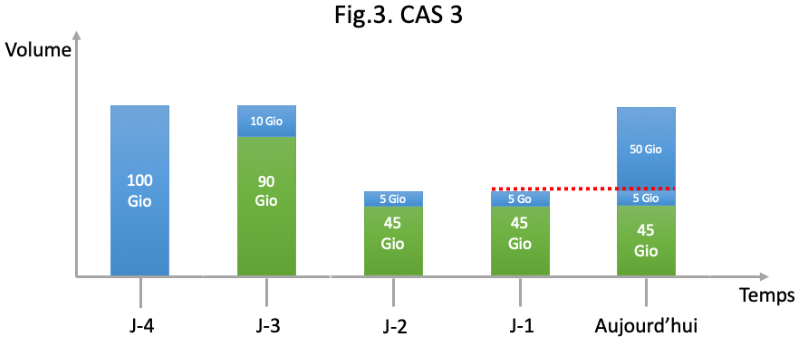
Cette fois, notre algorithme de facturation considère au jour j (Aujourd’hui) une valeur de donnée non dédupliquée plus importante :
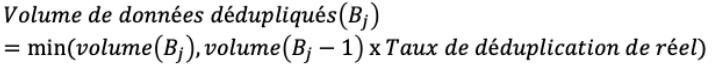
et donc :
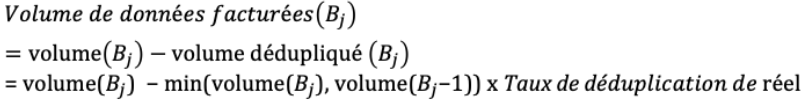
Dans ce cas, le volume total de sauvegarde facturable pour la machine sera donc :
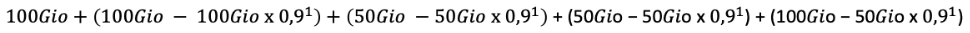
=
l'addition des volumes bleus (fig.3)
=
100Gio + 10Gio + 2 x 5Gio + 55Gio= 175Gio facturables
- Formule générale
Voici la formule mathématique que nous utilisons tous les jours afin de calculer les valeurs de consommation de sauvegarde.
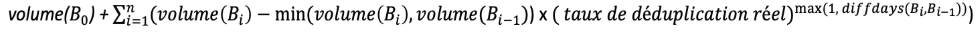
Avec:
B = sauvegarde
B0 = sauvegarde initiale
volume = taille de la sauvegarde en octets
diffdays (Bi, Bi-1) = Nombre de jours de différence entre la dernière sauvegarde (i-1) et la sauvegarde actuelle (i)
- Application à la facturation
La formule précédente permet d’estimer à un instant t la consommation d’un compte client à partir de ses sauvegardes présentes à cet instant dans l'environnement de sauvegarde.
Cet algorithme sera appliqué chaque jour sur toutes les machines. Les données facturables d'un compte pour un mois sont la somme des maximums de consommation quotidienne de chacune de leurs machines au cours de ce mois.
- Cas des politiques multiples sur un agent
Si un agent RG a plusieurs politiques, on regroupe ses sauvegardes par politiques avant d’appliquer l’algorithme de facturation sur chacune des politiques. La consommation de l’agent correspondra donc à la somme des maximums de consommation de chacune des politiques.